
Falsos Positivos dos Detetores de IA em Trabalhos Académicos: Os Números 2026
Um estudante de pós-graduação em Lisboa entrega a sua dissertação. Semanas depois, recebe uma notificação: o software de deteção de IA sinalizou o seu capítulo de metodologia como “provavelmente gerado por inteligência artificial”. O texto era integralmente humano. Situações como esta não são exceções — são, conforme mostram os dados de 2026, um padrão estrutural com raízes bem documentadas na literatura científica. O debate sobre o detetor de IA falso positivo em trabalhos académicos já não é hipotético: é estatístico, e os números são perturbadores.
Desde a adoção em massa de ferramentas como o GPTZero e o Turnitin AI Detection a partir de 2023, universidades de Portugal, Brasil e de todo o mundo confrontam-se com uma tensão crescente: a tecnologia que pretende garantir a integridade académica pode, paradoxalmente, punir estudantes que nunca usaram IA. Este artigo reúne os dados mais recentes, identifica quem corre mais risco e examina o que as instituições estão — ou não estão — a fazer a respeito.
O problema dos falsos positivos em contexto académico
Um falso positivo, no contexto da deteção de IA, ocorre quando um texto escrito por um ser humano é classificado como gerado por inteligência artificial. Ao contrário de um falso negativo — em que conteúdo gerado por IA passa despercebido — o falso positivo tem consequências diretas e imediatas para o estudante: abertura de processo disciplinar, reprovação na unidade curricular ou, em casos extremos, anulação do grau.
O problema tem três raízes técnicas identificadas na literatura:
- Perpexidade baixa: os detetores medem a “previsibilidade” estatística de um texto. Escrita académica estruturada, objetiva e formal — precisamente o que se espera numa tese — apresenta perplexidade baixa, o mesmo padrão que os modelos de linguagem tendem a produzir.
- Burstiness reduzida: humanos alternam entre frases longas e curtas de forma irregular; modelos de IA tendem a ser mais uniformes. Académicos que seguem rigidamente as normas de escrita científica também produzem textos com burstiness baixa.
- Deriva dos modelos de deteção: os detetores são treinados sobre corpora de IA de gerações anteriores. Com cada nova versão dos LLMs, a distribuição estatística muda e a calibração dos detetores perde validade.
Estas limitações não são segredos industriais: constam das próprias fichas técnicas das ferramentas e de múltiplos estudos revistos por pares publicados entre 2023 e 2025.
Taxas de falso positivo por ferramenta: GPTZero, Turnitin e outros
A tabela seguinte consolida os dados disponíveis de estudos independentes e de benchmarks publicados pelos próprios fornecedores. A diferença entre os dois tipos de fonte é, em si, um dado relevante.
| Ferramenta | FP (auto-declarado) | FP (estudos independentes) | Fonte |
|---|---|---|---|
| GPTZero | ≤ 1% | 6,4%–18% | GPTZero benchmarks (2025); Ryne.ai 100k+ textos (2025); EyeSift (2026) |
| Turnitin AI Detection | Não publicado | 10%–35% | EyeSift Benchmarks 2026; Hastewire (2025) |
| ZeroGPT | Não publicado | ~28% | Hastewire (2025) |
| Originality.ai | 0,5%–1,5% | 18%–22% | Originality.ai (2025); Hastewire (2025) |
| OpenAI Classifier | — | ~15% | Hastewire (2025) — ferramenta descontinuada em 2023 |
O padrão é consistente: quanto mais diversificada e realista a amostra, maior a taxa de falso positivo. Para uma tese de doutoramento em língua portuguesa, escrita segundo as normas APA ou ABNT, os rácios de erro observados em condições de laboratório controlado têm pouca relevância preditiva.
O viés linguístico: não-nativos de inglês em risco elevado
O estudo mais citado sobre este tópico — e o mais consequente para estudantes lusófonos — é o de Liang et al. (2023), publicado na revista Patterns (Cell Press) e resumido pelo Stanford Human-Centered AI Institute (HAI). Os investigadores submeteram 91 redações do TOEFL, escritas por estudantes não-nativos de inglês, a sete detetores de IA diferentes.
Fonte: Liang et al., “GPT detectors are biased against non-native English writers”, Patterns, Cell Press, 2023 — resumido pelo Stanford HAI.
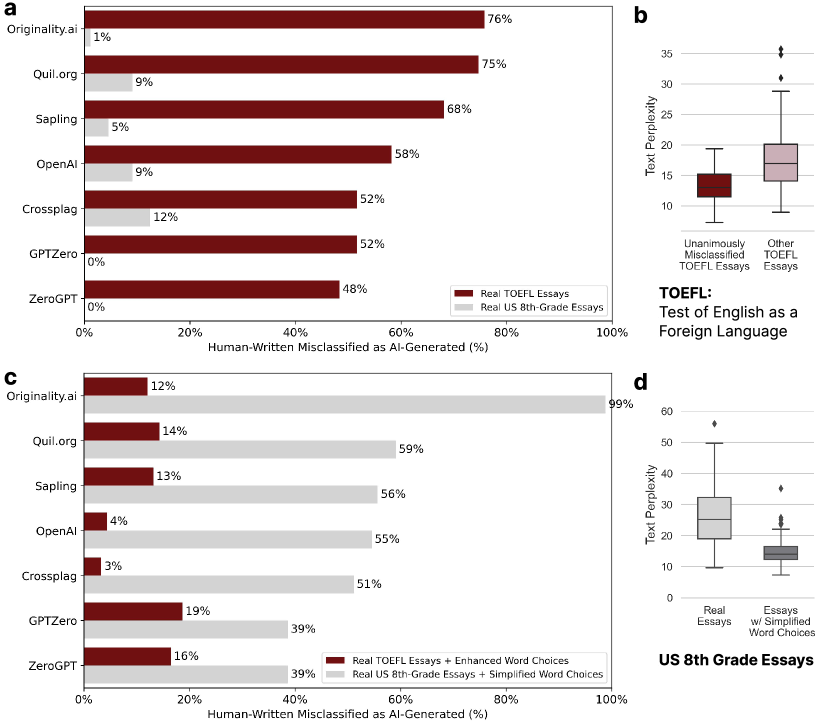
Os mecanismos deste viés são claros: os detetores baseiam-se em métricas de perplexidade e burstiness que penalizam vocabulário simples, estruturas sintáticas diretas e repetição de conectores. Estas são exatamente as características da escrita académica formal produzida por estudantes cuja língua materna não é o inglês — e, por extensão, de estudantes portugueses e brasileiros a escrever em inglês para revistas internacionais ou programas de duplo grau.
Adicionalmente, 89 das 91 redações (97,8%) foram sinalizadas por pelo menos um dos sete detetores testados. Isto significa que, num cenário de utilização múltipla de ferramentas — prática comum em comissões de avaliação que verificam resultados em vários sistemas —, quase qualquer texto de não-nativo seria marcado em pelo menos uma plataforma.
Para estudantes a redigir em português, o risco é igualmente real. Os detetores treinados maioritariamente sobre corpora em inglês generalizam mal para outras línguas, e os poucos modelos específicos para português têm bases de dados de treino substancialmente menores, o que amplifica a incerteza estatística.
O crescente uso de IA no ensino superior — documentado para Portugal em estudos recentes da Universidade de Coimbra, onde 80% dos alunos admitem usar IA para fins académicos — torna esta discussão ainda mais urgente: quanto mais estudantes usam IA de forma lícita (revisão gramatical, organização de referências, formatação), mais os seus textos “cheiram” a IA para estes sistemas.
Panorama em Portugal e no Brasil
Nem Portugal nem o Brasil dispõem, até à data de publicação deste artigo, de estatísticas nacionais publicadas sobre a taxa de falsos positivos em processos disciplinares por suspeita de uso de IA. O que existe são dados proxy que permitem estimar a dimensão do problema.
Portugal
De acordo com dados do levantamento sobre IA no ensino superior em Portugal e no Brasil (2026), entre 58% e 65% dos estudantes portugueses do ensino superior utilizam ferramentas de IA regularmente nos seus trabalhos académicos. Se a grande maioria destes usos é legítima (revisão, tradução, pesquisa assistida), e se os detetores exibem taxas de falso positivo de 6% a 35% sobre texto académico formal, a probabilidade de um falso alarme por submissão torna-se estatisticamente não negligenciável.
O contexto de reprovações por plágio em Portugal e no Brasil revela que os processos formais por plágio confirmado envolvem tipicamente múltiplas evidências corroborantes — não apenas o resultado de um detector. Ainda assim, a sinalização automática é frequentemente o ponto de partida da investigação, colocando o ónus da prova sobre o estudante.
A Unicamp, referência no debate brasileiro, já alertou publicamente: os seus próprios especialistas do Centro de Referência em Tecnologias de Inteligência Artificial reconhecem que “os softwares de deteção falham com frequência e acusam estudantes inocentes de forma injusta” — como documenta o Mettzer no seu guia sobre IA na universidade, que detalha as posições da USP, Unicamp e Unesp.
Brasil
No Brasil, onde 84% dos estudantes do ensino superior já utilizaram IA e apenas 32% receberam formação formal sobre uso responsável, o risco de exposição inadvertida a processos por falso positivo é estruturalmente elevado. Um estudante que usou IA exclusivamente para rever a gramática do seu TCC pode ter o trabalho sinalizado por um sistema que não distingue entre assistência editorial e geração de conteúdo.
A ausência de formação institucional cria um segundo problema: estudantes que não sabem que a sua escrita pode acionar um detetor — por ser demasiado formal, demasiado concisa ou demasiado uniforme — não têm estratégia de defesa preparada quando confrontados com um relatório de suspeita.
O que dizem as universidades
A resposta institucional divide-se em três abordagens distintas, com implicações diferentes para o risco de falso positivo.
1. Proibição e sanção automática
Algumas instituições adotaram políticas de tolerância zero para qualquer trabalho sinalizado por ferramentas de deteção, sem escrutínio adicional. Esta abordagem tem a vantagem da simplicidade operacional, mas maximiza o risco de dano injusto a estudantes inocentes. Não existem dados públicos sobre quantas reprovações neste modelo resultaram de falsos positivos.
2. Sinalização como ponto de partida para investigação
A abordagem recomendada pela maioria das associações académicas — e adotada pelas instituições de maior reputação — trata o resultado do detetor como indício, não como prova. O estudante é convocado para apresentar o processo de escrita (rascunhos, notas, historial de edições), e a decisão disciplinar resulta de uma análise holística.
3. Substituição da avaliação escrita por prova oral
A Unicamp, por exemplo, reforçou as componentes orais das suas avaliações precisamente porque os detetores são considerados insuficientemente fiáveis. A defesa presencial do trabalho — onde o estudante demonstra domínio aprofundado do tema — é vista como o controlo de autenticidade mais robusto disponível.
A Turnitin, por seu lado, afirma que os seus resultados “não devem ser usados como única base para decisões académicas” e recomenda que os educadores os interpretem como um ponto de partida, não uma conclusão. Esta ressalva, constante nos seus próprios materiais de apoio, é frequentemente ignorada na prática institucional.
Implicações para estudantes e para a política institucional
Os dados de 2026 apontam para cinco recomendações práticas, quer para estudantes quer para responsáveis académicos.
Para estudantes
- Documente o processo de escrita. Mantenha rascunhos datados, capturas de ecrã de pesquisas e o historial de revisões do processador de texto. Em caso de sinalização, este registo é a prova mais convincente de autoria humana.
- Conheça a política da sua instituição. Antes de usar qualquer ferramenta de IA — mesmo para revisão gramatical —, verifique se a sua universidade exige declaração e em que termos.
- Não assuma que “não usar IA” é proteção suficiente. Os dados mostram que textos humanos são regularmente sinalizados. Ter um processo documentado é uma precaução racional independentemente do uso de IA.
- Use ferramentas de escrita académica certificadas. Plataformas como a Tesify oferecem assistência a dissertações que preserva a voz e o processo do autor, minimizando o perfil de risco nos detetores.
Para instituições
- Adopte políticas de dupla evidência. Nenhum processo disciplinar deve resultar exclusivamente do output de um detetor de IA, dadas as taxas de falso positivo documentadas.
- Forme estudantes e docentes. A lacuna de literacia — onde apenas 32% dos estudantes brasileiros receberam formação sobre uso responsável de IA — aumenta desnecessariamente a exposição ao risco.
- Monitore a investigação sobre viés. As publicações do Stanford HAI e os relatórios do investigador Marco Mello sobre o impacto da IA nas comunidades de conhecimento oferecem enquadramento útil para gestores académicos avaliarem a fiabilidade destas ferramentas no tempo.
Perguntas Frequentes
O que é um falso positivo num detetor de IA?
Um falso positivo ocorre quando o detetor classifica um texto escrito por um humano como gerado por IA. Acontece porque os algoritmos de deteção medem padrões estatísticos — como perplexidade e uniformidade frásica — que podem estar presentes tanto em texto de IA como em escrita académica formal humana.
Qual é a taxa de falso positivo do GPTZero em condições reais?
O GPTZero publica uma taxa de falso positivo de ≤1% nos seus benchmarks controlados. Estudos independentes com amostras mais diversas encontraram taxas entre 6,4% e 18% em contextos reais. A diferença deve-se à composição das amostras de teste: textos de várias línguas, áreas disciplinares e registos formais aumentam sistematicamente o erro.
Estudantes não-nativos de inglês são mais afetados?
Sim, de forma significativa. O estudo de Liang et al. (2023), publicado na revista Patterns (Cell Press) e destacado pelo Stanford HAI, mostrou que 61,22% das redações do TOEFL escritas por não-nativos foram classificadas como IA por pelo menos um detetor. O mecanismo é o viés de perplexidade: vocabulário mais simples e estruturas diretas — comuns em não-nativos — são estatisticamente indistinguíveis do texto de IA para estes sistemas.
O Turnitin publica a sua taxa de falso positivo?
Não. A Turnitin não publica uma tabela comparativa de taxas de falso positivo. Os seus materiais de apoio reconhecem que o sistema “pode identificar incorretamente texto humano, gerado por IA, ou parafraseado por IA” e recomendam explicitamente que os resultados não sejam usados como única base para decisões académicas. Estudos independentes (EyeSift, 2026; Hastewire, 2025) estimam taxas de falso positivo entre 10% e 35%, dependendo do tipo de texto.
O que fazer se o meu trabalho for sinalizado por um detetor de IA?
Reúna evidências do processo de escrita: rascunhos anteriores datados, historial de versões do documento, notas de investigação e qualquer correspondência com o orientador sobre o trabalho. Solicite à instituição que o processo seja avaliado por um académico — não apenas pelo software — e, se necessário, peça uma prova oral para demonstrar o domínio do tema. A maioria das políticas institucionais estabelece que o resultado do detetor é apenas um indício, não uma prova conclusiva.
Escrever em português reduz o risco de falso positivo?
Não necessariamente. Os detetores de língua portuguesa têm bases de treino menores, o que pode tanto reduzir como ampliar a incerteza estatística. O risco é especialmente elevado em trabalhos com escrita académica muito padronizada (normas ABNT rigorosas, terminologia técnica repetitiva), que apresentam padrões de baixa perplexidade independentemente da língua. A recomendação mais robusta continua a ser documentar o processo de escrita, independentemente da língua de redação.
Escreva com confiança. Documente com rigor.
A Tesify foi concebida para apoiar estudantes e investigadores na produção de trabalhos académicos autenticamente seus. As nossas ferramentas preservam a sua voz, o seu raciocínio e o seu processo — os elementos que nenhum detetor de IA consegue fabricar.